声明:本文来自于微信公众号 电商在线(ID:dianshangmj),作者:王亚琪,授权站长之家转载发布。
中国的大模型,已经震惊了外国科技圈。
这不,这几天商量大模型的更新,直接让外国网友惊呼:太疯狂了,中国的AI界究竟还有多少我们不知道的巨变?

不怪这些网友太大惊小怪——最近全新升级的日日新·商量大模型5.0(SenseChat V5),在基础能力上再次重大更新,直接把大模型能力升级到新的阶段,直观印象可感的那种。
简单来就是,这款拥有强大逻辑推理能力的6000亿参数MoE模型,可以轻松地把你变成一个更好的打工人。
打工神器Part1:办公小浣熊
所以说了这么多,得到日日新5.0加持的产品,到底会有怎样非一般的体验?
首先,我们来看看最直击打工人痛点的「办公小浣熊」。
顾名思义,它主打的就是一个办公能力。

体验地址:https://raccoon.sensetime.com/office
众所周知,在真实的办公场景中,往往会有很多极其复杂的图表,就连我们人类自己看到都会晕头转向。
更何况还有不少资料只有外文的,更是增加了阅读障碍。
办公小浣熊可以hold住吗?
前两天,F1中国大奖赛刚刚落幕,而作为索伯技术合作方的商汤,更是提供了一些资料。
而我们也借此直接上了点难度:导入一份拥有60万条数据的「全英文」表格,涵盖F1历史各类数据信息,让它分析一下。
毫不夸张地说,这项测试非常难!
要知道,这份数据体量非常庞大。而且数据库中除了英文,还包含简写、划线-等复杂的元素。
比如,「周冠宇」对应的是「guanyu-zhou」(甚至不是guanyu zhou),信息模糊度比较高。
因此,对于模型来说,分析这样的数据并非是一件易事。
而我们也对这次的挑战,充满期待。
顺便说一嘴,商汤从2022年周冠宇第一次登上F1赛场开始,连续三年都是车队的技术合作伙伴
接下来,考验真本事的时候到了,我们给办公小浣熊下发任务:
给出周冠宇在2020-2024之间参与比赛数量的柱状图。
果不其然,在第一次尝试时,办公小浣熊无法从表中的英文名字「guanyu-zhou」匹配到周冠宇。
因此,它会认为图中没有周冠宇的信息。

下一步就得上点「提示」技巧了。
在接下来互动中,和它说「肯定会有的,你再找找」。

通过一步步的引导和互动,模型在我们的引导下学会了反思,然后成功地完成了任务!
可以看到,办公小浣熊通过努力思考,完成了所给任务的数据分析,并给出了相应的Python代码。

而这个交互过程也告诉我们,如果给模型的数据表格并不匹配、比较模糊,模型表现不尽如人意时,也不要放弃。通过互动,模型就很可能给我们惊喜,给出不一样的数据交互体验。
下面就是一个更难的任务,我们把F1历史上所有车手、车队、比赛、赛道、引擎制造商等等信息,导入数据库文件中,这个数据量是非常庞大的。
然后问模型:F1当中总共有多少车手?可以交叉表格进行计算。
这个任务,同样难度非常大,因为在所有字段中,没有任何一个是中文的。

最终,办公小浣熊用模糊的匹配,找到了相对应的信息——901位车手,这个答案完全正确!

在大模型产品中,办公小浣熊的这个表现,堪称高手中的高手。
在这个过程中,模型正是通过交互模式迭代的逻辑,多次查询了不同的表头,最终给出了能让我们理解的信息。
再换一个问题,「有哪些车手获得总冠军?并按获奖次数从高到低绘制柱状图」。
最终,模型整理出:获得最多总冠军的车手是汉密尔顿和舒马赫。

接下来,我们来看看它能不能从不同维度,统计出汉密尔顿和舒马赫的获奖情况。
办公小浣熊画了一个雷达图,清晰呈现出两人杆位数、圈数、领奖台数、胜利数等各维度的能力,汉密尔顿的次数还是略高于舒马赫。
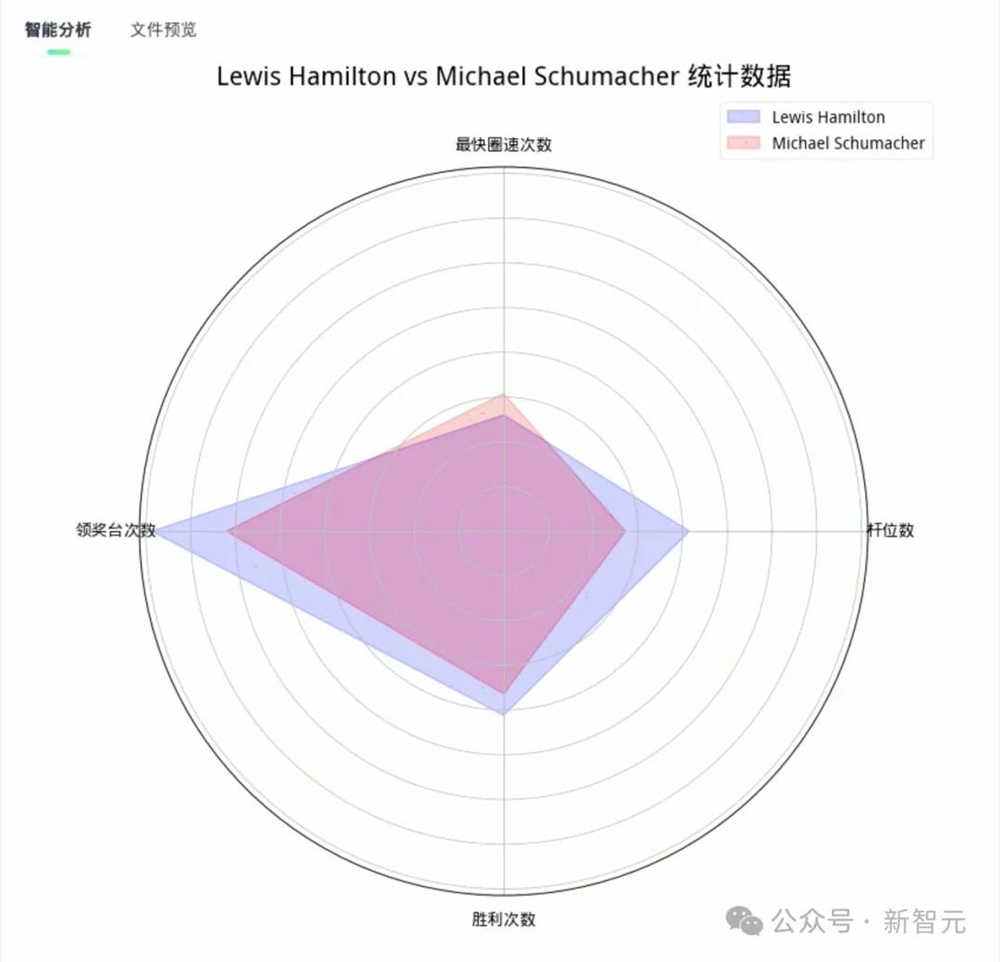
在这个真实的数据应用场景中,通过交互方式对复杂表格实现了联动,日日新5.0表现出的强大推理能力,令人印象着实深刻。
下面,再来一个同样高难度的市场采购的案例。
上传「2024年新增供应商相关信息」文档之后,要求它整合到一个表格中,并要求表头以列出供应商分类、供应商名称、产品名称...列出。
办公小浣熊立刻给出了一个完整、清晰的表格总结版。
甚至,它还可以为你生成一个可视化的柱状图,将IT类、固资类、营销类、行政类费用直观地呈现出来。

包括热力图这类图表生成,它也可以拿捏。

此外,我们还可以一并上传多个文档,让办公小浣熊继续完成要求的任务。
首先它给出了可查阅的代码,最后生成了不同类别需要采购的数据表格,一看即明了。

一通测试下来,小编的感慨就是:能用上如此高效的数据分析、总结办公神器,真是每位打工人的福音。
并且,它还是免费的!
打工神器Part2:文档大模型
另一个鲜明体现出日日新5.0能力的产品,就是商量-文档大模型。
据说,除了表格数据分析外,在长文本处理这个场景下,模型的能力也是一绝。
那我们就要来上难度了:丢给它一堆数学试卷,要求它从中找出一道解一元一次方程的解答题。
很快,它不仅从「小学数学试卷」的第五部分找到了对应的题型,甚至还麻溜地给出了解题过程。

我们还可以对它要求,再帮忙出一道类似的题目,但题型得是选择题。
它不光给出了题干,还顺便给出了正确答案和解题步骤。

再比如,上传一份小学试卷,让文档大模型帮你以小学生的理解力,去分析其中的一道应用题。

它可以像一位耐心的老师,指导学生做题一样,从步骤1、2、3详细地分析了缜密的解题过程,并给出了答案。
这样的AI老师,有谁不爱?

然后,文档大模型还可以是「出题机」,能给出一道类似的题目,可以充分锻炼自己举一反三的能力。
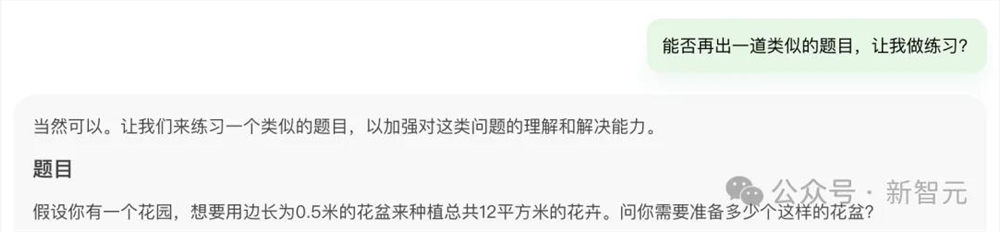
你还可以将自己做完试题的结果,告诉它,让它为你打分。
显然,8.4÷0.4=2.1答案不正确,正解应该是21。

就着这个文档,你可以无限提问。
文档大模型在题目几乎糊在一块儿的页面中,不仅能准确识别你想要的题目,还能悉心给出解答。

给它上传一份唐诗三百首和宋词三百首,我们就可以根据这些文件提问了!

比如,找出描写月亮的诗词。
它迅速找出了《静夜思》《望月怀远》《水调歌头.丙辰中秋》等作品。

下面,我们还可以来一个拔高性的提问:月亮在唐诗和宋词中的内涵有哪些异同点?
它回答道:相同点在于都是情感寄托、时光流转的象征和美的象征,不同点就在于表现手法、情感深度和文化背景的不同。

要问小编每天起早贪黑地辛苦打工,最爱听到的词是啥?大家异口同声的三个字就是——
10W+!
10w+的文章,到底有哪些套路呢?让文档大模型帮我们来分析一下。
以下是五篇10w+公众号爆款文章(没错,看名字就知道了)。

让我们把它们一次性扔给文档大模型。首先,它可以帮我们总结出每篇文章的摘要。

互联网文章千千万,为什么偏偏是它们成了爆款?
文档大模型分析后总结道:贴近生活的真实故事,一下子就让读者找到了自己的影子,产生了强烈的情感连接。
挖掘出人类共通的情感体验,再提供不同的观察视角,就会让文章有较高的思考价值。

所以,根据上述经验,我们如何炮制出类似的爆款呢?文档大模型提供了以下思路——
疫情下的亲子关系新常态;远程工作时代的职场妈妈;数字断舍离;老钱风到新钱风;人工智能时代的职业转型之路……

好家伙,这些命题听起来个个都很吸睛,已经忍不住想看了!下一步,就是码出几千字,篇篇十万加,走上人生巅峰了。
文档大模型这种超强的文本分析能力,甚至可以为文史哲的同学们写严肃论文提供思路。
比如,《论语》和《道德经》关于「德」的观点,有何异同?
文档大模型在咀嚼了长达29页21638个字的《论语》和14页7302个字的《道德经》后,分析出——
相同点在于,二者都高度重视「德」在个人修养和社会治理中的作用;区别在于,《论语》中的「德」更多关联到个人,后者还涉及到顺应自然、无为而治的理念。

如果想深入研究,应该阅读那些参考文章和书籍?文档大模型列出了相关领域的经典著作。

更厉害的来了,如果把两个文档的思想整合,能得到怎样的启发呢?文档大模型表示,可以从和谐共生的生活哲学、内在修养与外在行为的统一等方面入手。
沿着这个思路深入探讨下去,或许就能肝出一篇观点别具一格的学术论文了。

一大波Benchmark袭来
当然,除了打工之外,对于各种刁钻的测试,日日新5.0也没在怕的。
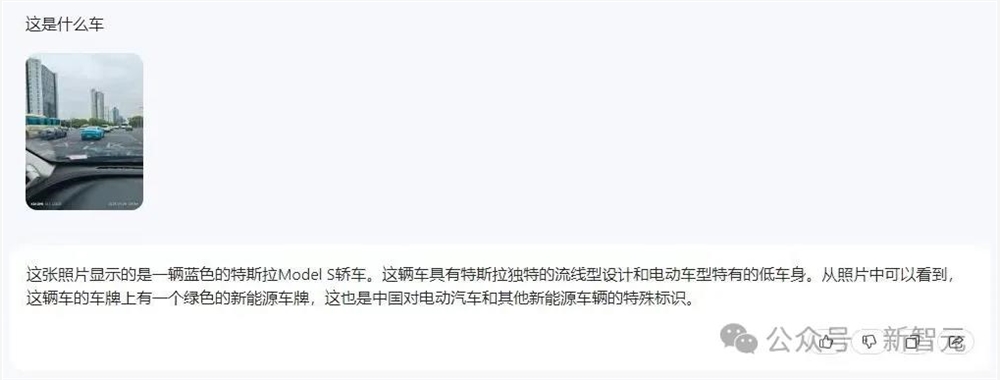
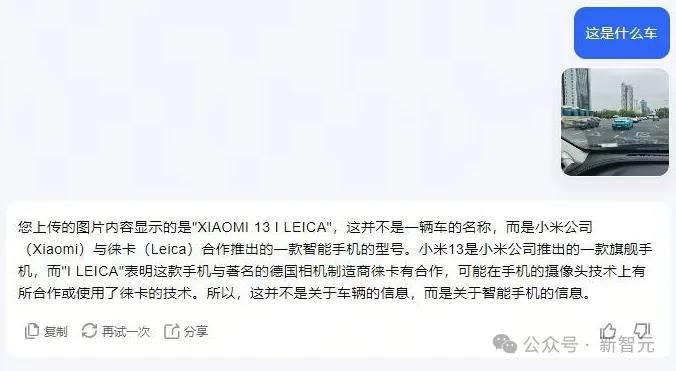
首先我们来看一张新鲜出炉的小米SU7照片。
因为是随手抓拍的,车辆本体其实很小。
不过,在日日新5.0加持下的商量,很轻松地就识别出了车型,而且还附上了一波详细的介绍,非常专业。

相比之下,其他的模型就直接GG了。
要么是认错了车,要么连车都没看到,只识别出了照片的水印。
接下来,向我们走来的,就是日日新5.0大战「弱智吧」难题。
「只切一刀,如何把四个橘子平均分给四个小朋友?」
商量为了公平起见,只切一刀还是得将四个橘子排成一排。这样,一刀下去,每个小朋友还是一人一个橘子。

这招真是高明!
接下来,则是一道非常「正经」的推理题。
「一个猎人向南走了一英里,再向东走了一英里,然后向北走了一英里,最终回到了出发点。他看到一只熊并开枪打死了它。这只熊是什么颜色」?
商量一语中的,说出了这道题实际上是——地理谜语。

因为只有在极点的时候,猎人才能听起来这么曲折的路程,回到出发点。
也就是说,这只熊一定是北极熊了。
5次模型迭代,全面对标GPT-4Turbo
一波测试下来,想必你也对升级后的日日新5.0能力,有了大概的了解。
下图是一张对行业里模型的横评。
注意看,图中有一个亮点:最近的行业模型迭代,在纯粹知识型能力上提升没有那么显著,但在高阶推理,尤其是数学能力上,有了很大提升。
比如,GPT-3.5到GPT-4的提升有100%之多,而Llama2到Llama3,直接提升了400%之多。
这是因为,大部分用来提升数据质量的能力都构建在了推理能力上,并且是合成数据的推理。
尤其对于领域应用的落地而言,高阶推理能力更是成了行业大模型能力推进的重要指标。

日日新5.0在大部分核心测试集指标上,都已对标甚至超过了GPT-4Turbo
让我们重回到这些评测上,不难看出,日日新5.0在语言、知识、推理、数学、代码等能力上,都有了一波明显的。
而在主流客观评测上,它已经达到甚至超越了GPT-4Turbo的水平!
正如前文所说,日日新5.0如此之强的能力,靠的就是商汤团队在模型架构,以及数据配方上的持续优化。
从日日新1.0、到2.0、3.0、4.0,以及今天5.0的发布,每一次版本重大的迭代,背后核心都是——数据的升级。
过去一年里,商汤花了大量时间去完成了语料质量的优化,搭建了完善的数据清洗的链条。
对于5.0版本,他们重点关注了数据集中,是否蕴含比较丰富的逻辑。
通过对有高信息密度,逻辑性强的语料给予更高的权重,并对整体语料进行了高质量清洗,从而实现性能提升。
具体来说,商汤在知识层面上,采用了超10T的Token,保证了LLM对客观知识和世界的初级认知。
除此以外,商汤还合成了数千亿的思维链数据,成为日日新5.0性能提升,对标GPT-4Turbo的关键。x
在内部,合成数据方式经历了两次迭代,从最初用GPT-4来合成数据,过渡到用自己模型中间版本合成数据,再进行训练的过程。
其中,商汤90%的合成数据是自家模型生成的,另外10%的数据由世界顶尖LLM生成。
由此,便可以得到非常高质量的数千亿合成数据。

这几天,奥特曼在斯坦福闭门演讲中谈到,「Scaling Law依旧有效,GPT-5要比GPT-4更强大,GPT-6也远远超越GPT-5,我们还没有到达这条曲线的顶端」。

也就是说,大模型下一步发展的空间潜力,将是无穷无尽的。
还真是有点期待日日新6.0的诞生了。
参考资料:
https://chat.sensetime.com/
()
(来源:站长之家)
免责声明:本站文章部分内容为本站原创,另有部分容来源于第三方或整理自互联网,其中转载部分仅供展示,不拥有所有权,不代表本站观点立场,也不构成任何其他建议,对其内容、文字的真实性、完整性、及时性不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容,不承担相关法律责任。如发现本站文章、图片等内容有涉及版权/违法违规或其他不适合的内容, 请及时联系我们进行处理。
 宣传片
宣传片
 QQ:
QQ: 微信:
微信:



 公安网备案:苏ICP备2022030477号-15苏州钰尚网络文化传媒有限公司
公安网备案:苏ICP备2022030477号-15苏州钰尚网络文化传媒有限公司